
研究テーマ紹介(和崎)
![]()
●概要
情報システムにおける「セキュリティ(security)」に関しては,暗号化通信・ファイルシステムに代表される「安全性(safety)」とともに,システムの信頼性・堅牢性(reliability)の確保が大変重要である.非同期に動作する通信プロトコルやハードウェアなど,並列システムの設計とその動作検証は一般に難しく,モデル化・設計・検証の能力を向上させる必要がある.
私が指導可能な分野は「数理情報工学」であり,特に,並列システムモデル(concurrent system models)とそのモデル化手法(ネット指向設計,プロセス代数仕様設計,等),ならびにその形式検証系(定理証明系,モデル検査系)を基盤理論とし,ソフトウェアの上流設計や,上位ハードウェアコンパイラ、ペトリネット設計・検証ツールといった応用に取り組んでいる.
現在のところ実施中ならびに今後指導を予定しているテーマとしては,大別して以下の5つが挙げられる.
[1] 非同期並列システムのモデルと検証
[2] 関数型言語と定理証明系の融合による新しい検証系
[3] 上位記述とハードウェアコンパイラ
[4]
UML上流設計からモデル検査系までの一貫設計検証環境
[5] MPI/PCクラスタ・GPGPUによる並列処理
●1. 非同期並列システムのモデルと検証
非同期チャネルで相互に結合され,並行動作するプロセスを,仕様に基づいて記述し,その動作検証を行うことは重要である.
プロセスのモデルには,以下のような手法がある.
(1) セルオートマトン(cellular automaton, network automata)
(2) ペトリネット(Petri net)
(3) プロセス代数仕様(BLA : Basic-LOTOS oriented Algebra, CCS, CSP)
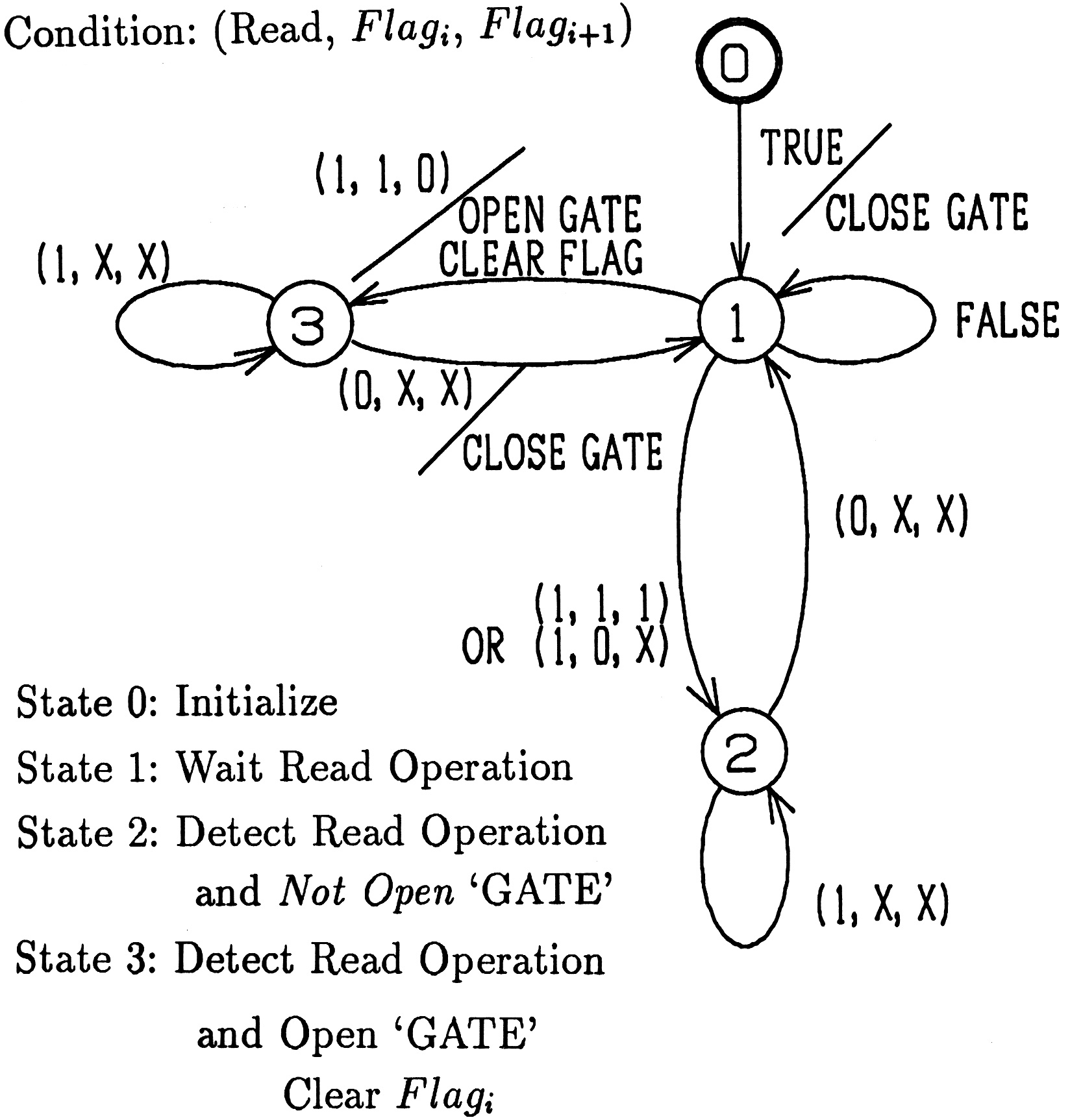
(1) セルオートマトン
セルオートマトンとは,一つの(有限)状態遷移機械(automata)を「セル(cell)」とし,それをn個定義したものである.次に,n個のcell_i(i=1,...,n)を協調・同期動作させるための,同期化ラベル積(Synchronized
product)を定義する.通常のautomataについての相互関係を拡張するだけなので,classicな同期型順序回路から出発したボトムアップ設計で使われてきたモデル化手法である.ハードウェア上への並列プロセッサ要素(PE)の,繰り返し構造を有するような実装は容易(図1.1,図1.2)であるが,設計時の同期化ラベル積の扱いは難しく,記述性が低い.
→もっと詳しく【解説】
 |
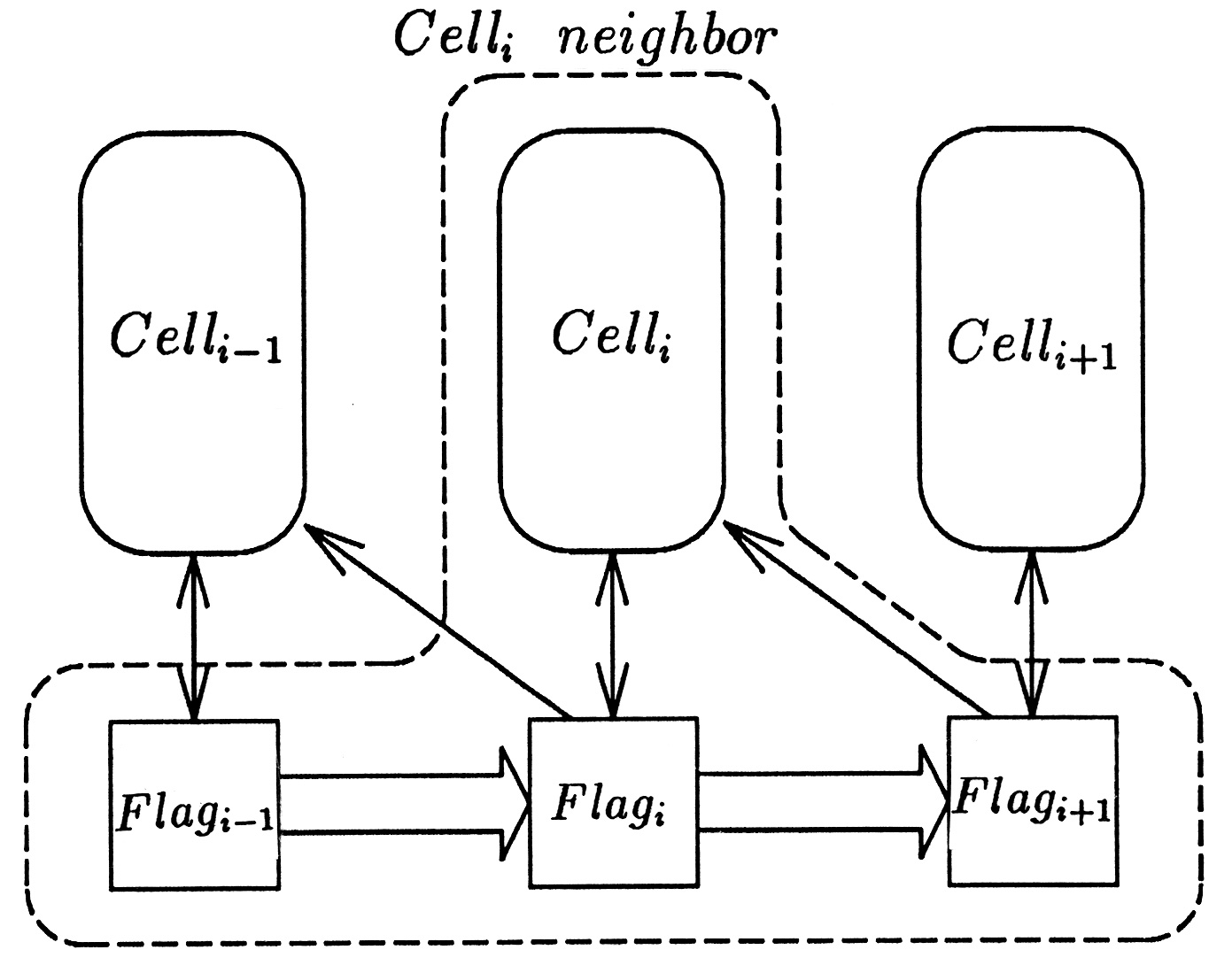 |
図1.1 セル型FIFOモデルの各FSM |
図1.2 セル型FIFOモデルの1次元順次接続図 |
→一時故障からの自己回復能力を有する通信バッファの設計例(資料1)【PPT】
(2) ペトリネット
ペトリネットは,並行動作する離散事象システムのモデル化手法の一つである.システム資源を表す「プレース」,システムの生成する事象を表す「トランジション」,資源と事象との間の関係を結ぶ「アーク」,ならびにシステム内のデータフローを表現し駆動するための「マーク」から構成される数学モデルである.簡単なネット構造のため,構造的あるいは動的な,様々な性質について解析性が高い.また,各要素を結んだネット図は,視覚的にもシステムの「振る舞い」を理解するための助けになる(図1.3).
→もっと詳しく【解説】
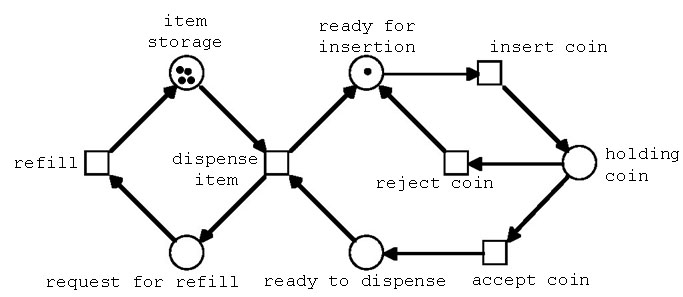
図1.3 自動販売機のモデル(FC-PNクラス:在庫数=4)
しかしながら階層型ネット構造はシステム内のインスタンス(実体)が増加すると記述性が低下する.また,data typing(データ型)に関する概念や操作がない.時間付き階層型ペトリネットを設計・解析・シミュレーション実行するための環境として,HiPSと呼ぶ統合環境を開発した.開発言語はC#を使用している.時間付きマーキングの機能を,論理ゲート素子の遅延要素として適用し,新たなゲートの振る舞いモデルを定義し,階層化することで複雑な組み合わせ論理回路を構成した.
最近は,トークンにデータ型(構造)を付与し,トランジション発火時のガード条件を論理式で与えるように拡張した高水準ペトリネット(カラーペトリネット)に関して,これの設計と可達グラフ生成,ならびにランダムウォーク・シミュレーションが可能なように機能拡張した HiPS2 を開発中である(図1.4).拡張ツールを用いて,並列ロボット制御のUML上流設計からの構造解析やエラーフィードバック,LEGOマインドストーム NXTマイクロコントローラ制御のための自動プログラム生成などへの発展を実施中である.
→もっと詳しく(資料1.1) (資料1.2)(資料1.3) 【PPT】
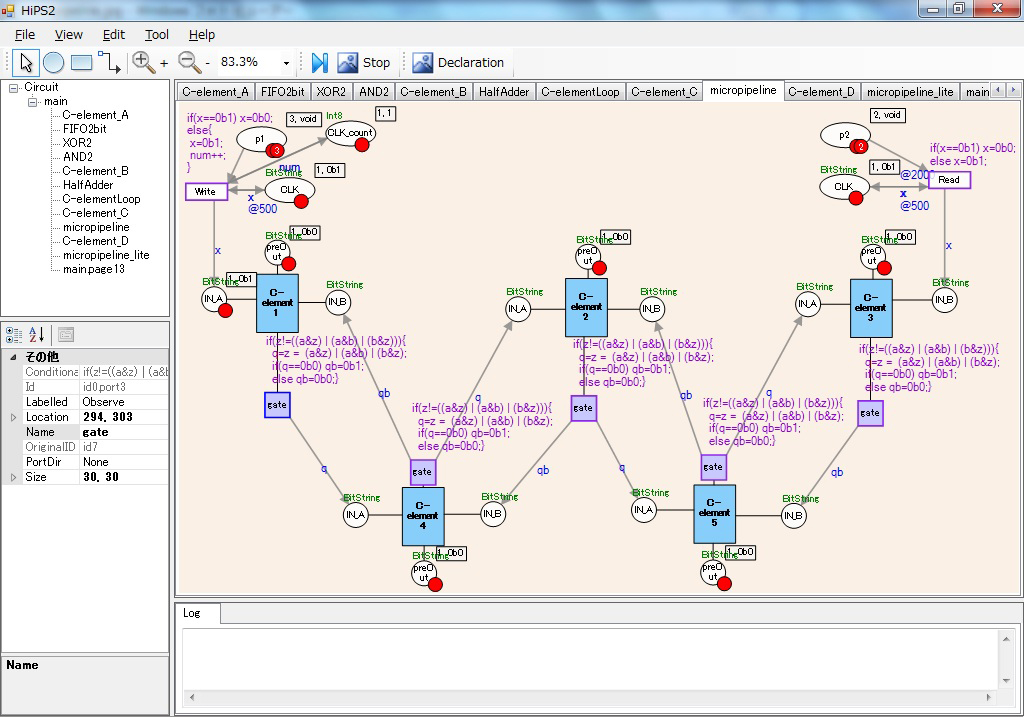
図1.4 高水準ペトリネット統合設計・解析・シミュレーション環境:HiPS2
(3) プロセス代数による合成手法
プロセス代数手法は,システムをプロセス(process)の群としてとらえ,相互のメッセージ通信を用いて同期化して全体を構成する方法がある.プロセスとは,動作(action)の列のことである.動作によって,メッセージを送ったり,受け取ったりする.各プロセスの定義は,プロセス代数仕様(Basic-LOTOS
oriented Algebra(BLA))を用いる.BLAにACT-ONEと呼ぶ抽象データ型(abstract data typing)の拡張を行ったものが,(Full-)LOTOSである.LOTOSの言語仕様は,ISO8807として国際標準となっている(図1.5).LOTOSの
process algebraic part は,
・CCS : Milner's Calculus of Communicating Systems
・CSP : Hoare's Communicating Sequential Processes
に基づいている.並列抽象機械,メッセージ通信によるプロセス定義,についての詳しい知識を欲する場合,これをぜひ読んでおこう.
→もっと詳しく 【解説】
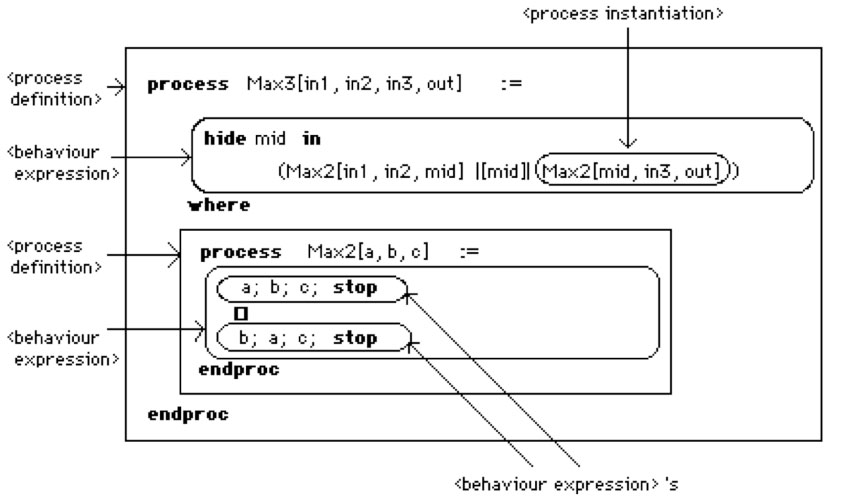
図1.5 LOTOSにおけるプロセス定義と並列合成の記述例
(Bolognesi,T. and Brinksma,E.,"Introduction to the ISO Specification Language LOTOS", Jan.1987より転載)
プロセス代数でモデル化したシステムは,その振る舞い(behaviour)をトレースしたグラフ,つまりLTS(Labelled Transition
System)を生成する.このLTSについて種々の性質の検証を行う.この手法のことをモデルチェッキング(model checking)と呼ぶ.先述のセルオートマトンを出発点とし,そのトレースグラフを
Kripke構造<状態値,遷移関数,atomic propositionの組>によって生成する場合もある.プロセス代数設計を出発点とした場合,LTS構造<状態値,アーク,ラベル付きトランジションの組>によって生成される.検証したい諸性質(例えば,BUS
arbiterの場合で,同時に2つ以上のノードにバス獲得権をアサートしない,など)は,modalな時相論理系(μ-calculas,CTL(computational
tree logic),ACTLなど)で記述する.ターゲットとなるLTSの状態空間について,性質を記述した時相論理式が満たすか否かを探索する操作(グラフ走査アルゴリズム)が重要である.また,予め状態空間を種々のグラフ縮小手法をもちいてサイズを小さくしたり(state
space reduction),あるいは先のLTS生成と同時に,時相論理式が満たすか否かを同時にチェックする手法(on-the-fly model
checking)も重要である.LOTOSからのLTS生成,グラフ縮約,デッドロック解析,時相論理を用いたモデル検査器については,INRIA/VASY研究所(France)で開発中のCADP toolboxを利用して研究を行っている(図1.6).
→もっと詳しく 【解説】
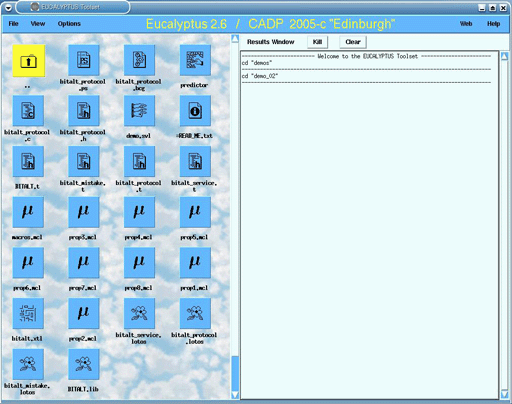
図1.6 LOTOS統合設計・検証環境:CADP toolbox (Xeuca GUIのスクリーンショット)
従来研究として,OCaml関数型言語を台言語とした上位コンパイラ(HDCaml)を用いて,streaming processing アルゴリズムのための上流設計を書き,それをLOTOS陽仕様記述言語へ自動コード生成するプロジェクトを実施した.ただし,CADP側の実装上の理由により,LOTOSコードはADT抽象データ型のチェックに留まっており,動的解析・モデル検査まで一貫実行できるまでには至っていない.
→Automatically Generation of N-bit Logic Circuit Components in Extended LOTOS(資料1) 【PPT】
★キーワード
・セルオートマトン,ペトリネット,プロセス代数仕様
・非同期並列システム,behaviour-based system verification
・LTS generation,状態空間探査,グラフ縮小
・時相論理系
・モデルチェッキング,システム形式検証系
・exhaustive or on-the-fly model checking
★このテーマに関する参考資料
[1] 参考資料・リンク集:並行プロセスのモデル化と検証&プロセス代数設計(LOTOS)
[2] Protocol
Verification by using LOTOS and Tools (part 1)
[3] Communicating Sequential
Processes C.A.R. Hoare, Prentice-Hall, 1985.
[4] CADP toolbox : A
Software Engineering Toolbox for Protocols and Distributed Systems
[5] NuSMV model checker : A new
symbolic model checker (open sources)
●2. 関数型言語と定理証明系の融合による新しい検証系
ObjectCamlなどの関数型言語を台言語として,アルゴリズム改善のための(超)上流設計を書き,それをLOTOSなどの陽仕様(Explicit Specification)記述言語へ直接コード生成するプロジェクトを実施している.その際,同時にシステムが満たすべき要件を陰仕様(Implicit Specification)で記述し,定理証明系で別途検査することが必要となってくる.
陽仕様とその設計から構成される,モデル検証系について考える.並行プロセスのモデル化と検証 で使用する,各種モデル検証系は,システムの「振る舞い」の検査を対象としたもの(behaviour-based system verification)である.したがって,観測可能なプロセス内のアクションの列(言い換えれば,ソフトウェアの各種プロシージャ,ハードウェアの各信号線の状態,など)の時系列における性質が検証可能,ということである.これの検証系が,生成したLTS状態空間の探査アルゴリズムを実装した検証系に他ならない.
しかしながら,このモデルチェッキング検証系は,その内部の演算機構や,あるいはそのデータ型における演算・操作が「正しく行われているか否か」の検証は行わない.なぜならば,生成したLTSにおいて,たとえばFull-LOTOSで記述した抽象データ型は,単なるシンボル(例:!val1, !val2, ... など)としか見做されておらず,そのデータが順序であるならば値の比較は行われるにせよ,演算(例:加算,乗算,除算,剰余など)の結果が正しいか,そのデータ型の内部で閉じているか否かの検証は行わない.更に付け加えると,加算の演算操作シンボルは"+"であって,アクション列のひとつとして「加算」という振る舞いが行われることを保証している.つまり,その"+"が最終に実装されたシステム上で,「どのように実装されているのか」あるいは「正しく加算を行うのか」という保証は得られないのである.
上記の理由により,モデルチェッキング検証における系の補強の方策として,各種演算を対象とした操作の正当性の検証を別の形式化数学検証系にてチェックしたい,というのがこの課題である.具体的には,Mizar proof checkerを使用して,
・各種演算(加算,減算,乗算,剰余など)のハードウェアを想定した実装(論理演算回路)の正当性検証(図2.1〜図2.3)
・グラフ縮小の各種手法(Ordered-BDD,partial order/bisimulation/observational reduction)などのアルゴリズム検証
・write-once, non-overwritingな計算機モデルと,Pursuit-possibilityを有するプロセス代数→LTS生成のframeworkとの関連
などを行う.
→もっと詳しく 【解説】
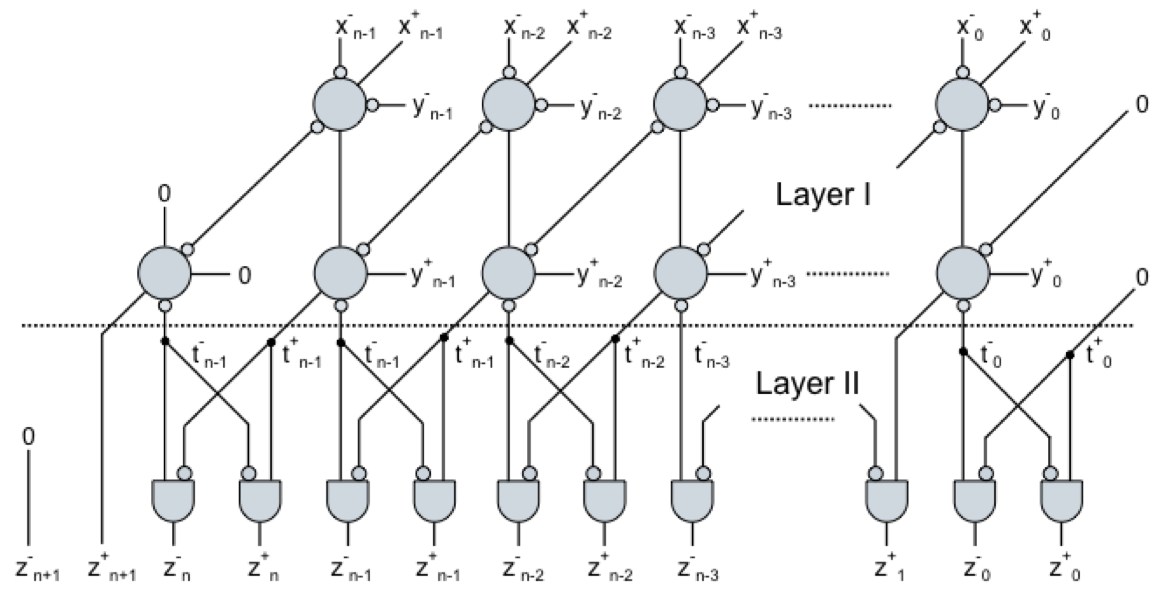
図2.1 冗長2進並列加算回路の構造(シンボル○:汎化加算器)

図2.2 数学構造(多ソート代数)に基づいて回路構造と合成を定義し,動作の正当性と安定性に関する諸定理を記述

図2.3 定理証明系向け形式化記述言語(Mizar)によって,厳密証明を書いた後,プルーフチェックを行う
→Mizar プルーフチェッカーを用いた冗長 2 進加算回路の検証(資料2.1)【論文】
★キーワード
・形式検証(Formal Verification)
・description-based verification 例:Mizar,HOLなど
・automated reasoning-based verification 例:Model Checkingなど
・問題の抽象化,自然数オーダでのモデル検証
・BDD,LTS,時相論理仕様記述
★このテーマに関する参考資料
[1] 参考資料・リンク集:形式化数学検証系(MIZAR)
[2] Mizar : proof ckecking system
[3] HOL : interactive
theorem proving in a higher-order logic
●3. 上位記述・ハードウェアコンパイラ
ハードウェア設計において,関数型言語ならびにC++を台言語とした,HDLの上位言語を定義し,コンパイラを作成している.コンパイラの生成コードとしては,Verilog-HDL, VHDL, .C ならびにモデルチェッキング検証系向けコード(NuSMV)などを想定している.
上位言語で一旦仕様を書いたあとは,用途に応じたコード生成を,元の仕様の書き換え無しに得ることが可能となる.また,仕様にシステム要求を(何らかの時相論理式を用いて)併記しておくことで,システムの動作と満たすべき要求仕様を,ひとつの上位言語上で閉じることが可能となる.
現在,モデル検査に対応する上位ハードウェア記述言語”Melasy”の設計と実装について研究を実施している.
機能設計後,高級言語で対象システムを実装し,コード生成によって対象システム向けのオブジェクトや実行可能モジュールを得るための,コンパイラが開発されている.ハードウェアの設計を記述するための比較的高度な言語によって書かれたコードから,直接,回路の構成情報を生成するコンパイラ(ハードウェアコンパイラ)が開発され,業界標準として使われている.
ハードウェア設計の正当性を形式的にチェックするツールとしては,SMV,NuSMV等のモデル検査ツール (Model Checker) が存在する.これらのツールを用いることで設計の正当性の評価を自動で行うことができる.しかし,NuSMVによって実ハードウェアの設計を全て記述するには,極めて低級な言語を利用しなければならず,VHDLやVerilog等の言語で設計したシステムを,検証目的のために,改めてNuSMV 等の言語で記述しなおす工程が新たに発生する.また,同じ設計を異なる言語で複数回行うことは,実際の開発現場の状況に鑑みるとコスト・納期などの制約において困難である.
SystemCを用いた開発では,ソフトウェアとハードウェアの協調設計を行うことが可能である.これは,一つのシステムの開発にソフトウェアとハードウェアの部分を分けながら,設計は協調して行う手法である.これにより,アルゴリズムが複雑でハードウェアによる実装が難しい処理はソフトウェアで行い,ソフトウェア (MPU) で実装すると演算時間のかかるような処理部分はハードウェアによる並列化やパイプライン等の工夫によって,高速に処理できるよう設計することが可能となる.しかしながら,この方法においても,ソフトウェア処理部分の設計と,ハードウェア処理部分の設計は,各々の設計を書く必要がある.そのため,ソフト,ハード部のいずれかに仕様の変更が出た場合,もう一方の設計も修正する必要があり,仕様変更に伴って発生するコストの増大が問題となる.
本研究では,既存のハードウェア記述言語,モデル検査用の言語,ならびにシミュレーションや協調設計向けのC言語向けのコード生成器を有するような,上位ハードウェア記述言語 "Melasy" の提案と言語設計を行った.この上位言語系は,関数型プログラミング言語 Haskellとその上のパーサライブラリParsecを使用し,コンパイラ処理系を実装した.上位言語によっていったん記述したシステムは,その設計からコード生成する先の言語を選択することにより,様々な対象オブジェクトコードを得ることができる.とりわけ,システムの設計とそれが満たすべき仕様を併せて上位言語で記述し,直接モデル検査ツール(SMV) 向けのコードを生成することに成功した(図3.1,図3.2).
次に,C++を台言語とし,XML中間系を経由してコード生成を行い,様々な言語向けのオブジェクトコードを生成する新しいバージョン "Melasy+" を開発中である.Melasy+では,上位記述に「仕様パターン」を埋め込み,繰り返し構造や信号線ラベルを解決した上で,XML中間系と同時にラベル解決済みの「仕様パターン」を生成することも検討している.
現在の従来の手法で困難さが生じていた問題が解決できる範囲,あるいは,上位言語Melasyによる設計では,どのような構文上の利点や記述性が優れているのか等に関して,種々のケーススタディによって比較・評価を行っている.
→もっと詳しく(資料3.1) (資料3.2)【PPT】
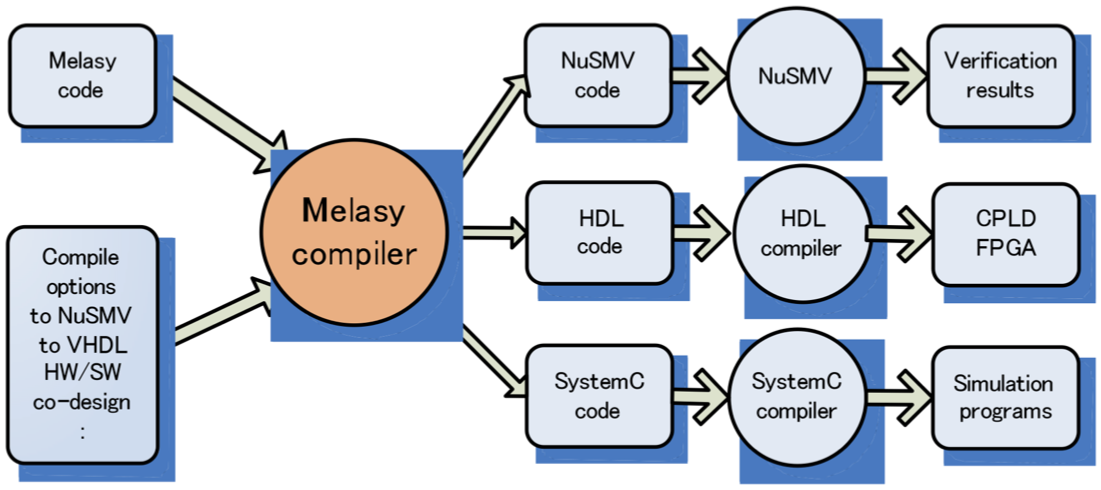
図3.1 上位記述言語 Melasy の位置づけ:設計+仕様を入力,様々な対象コードを出力する
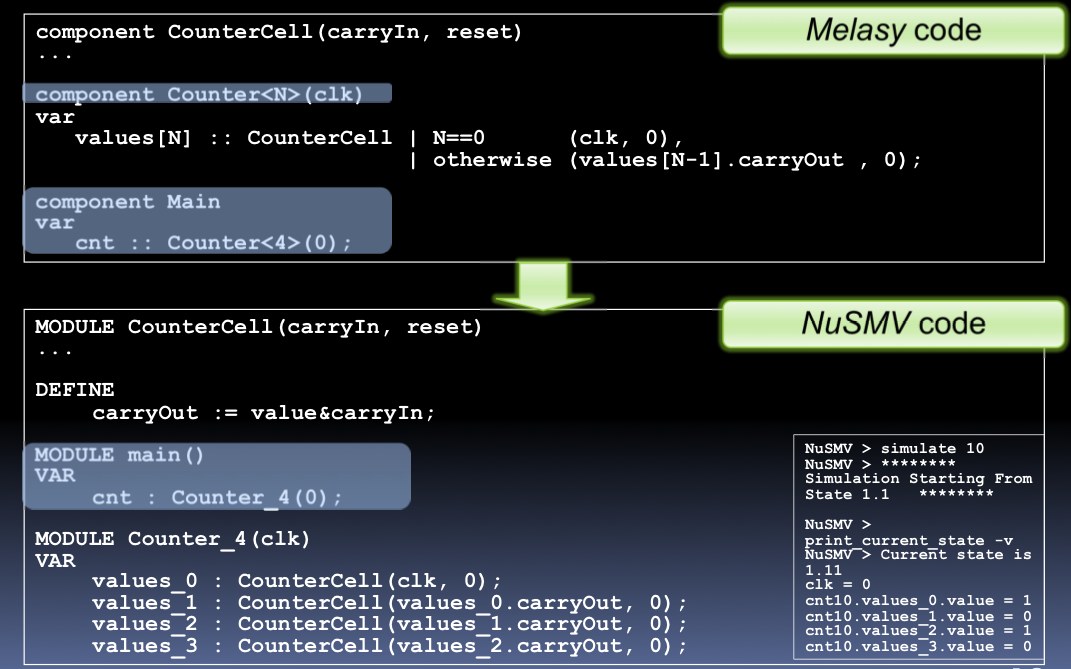
図3.2 Melasy上位記述から,モデル検査用言語NuSMVへのコード生成例(Nビットカウンタ)
★キーワード
・形式検証・モデル検査
・ハードウェア設計言語(hardware description language : HDL)
・上位記述(meta description)
・コード生成(code generation)
・仕様パターン(spec pattern)
★このテーマに関する参考資料
[1] E.M.Clarke, O.Grumberg and D.Peled, ``Model Checking'', MIT Press (2000).
[2] N.Iwasaki and K.Wasaki, ``A Meta Hardware Description Language
Melasy for Model-Checking Systems'', Proc. of 5th Int'l Conf. on
Info. Tech.:New Generations (ITNG2008), 273-278 (2008).
[3] NuSMV model checker : A new
symbolic model checker (open sources)
●4. UML上流設計からモデル検査系までの一貫設計検証環境
SPINモデル検査器を実行するには,専用の仕様記述言語PROMELAで対象モデルを記述する.また,検査対象の仕様の記述には線形時相論理(LTL)式を用いる.本研究では,システム開発の上流設計段階で使われるUML図を,PROMELAコード及びLTL式に自動変換する手法を提案する.UMLのステートマシン図と配置図を組みで利用し,ステートマシン図に,対象モデルの振る舞いや配置状況,要求仕様を記述し,PROMELAコードへの自動変換を実現する.一方,要求仕様として,UMLのシーケンス図を仕様パターンに準拠した記法に制限・展開することで,LTL式の自動生成を実現する.以上の機能を有する援用ツール群を試作し,ある通信プロトコルを対象とした上位設計に対する自動変換を実施し,評価を行った.
→もっと詳しく(資料4.1)【PPT】
(1) UML と SPIN モデル検査器
(2) UML から SPIN 用プロセス定義への自動変換
(3) UML から線形時相論理式への自動変換
(1) UML と SPIN モデル検査器
UMLは,OMG (Object Management Group) により管理されている仕様記述言語である.本研究では,UMLで定義された13種類の図の中でステートマシン図と配置図を使用し,システムをモデリングする.ステートマシン図は,モデルの状態変化を状態遷移として表現する図である。配置図は,システムに用いられる物理的な要素の,配置状態を記述する図法である.インスタンス間の通信路の接続状況や,インスタンスの物理的な数などを記述する.シーケンス図は対象モデルの時系列での動的な流れを記述できる.複合フラグメントを用いることで,モデルの制御構造を記述できる.複合フラグメント要素は,内部に新たな複合フラグメント要素を記述することで,入れ子の構造が記述できる(図4.1).
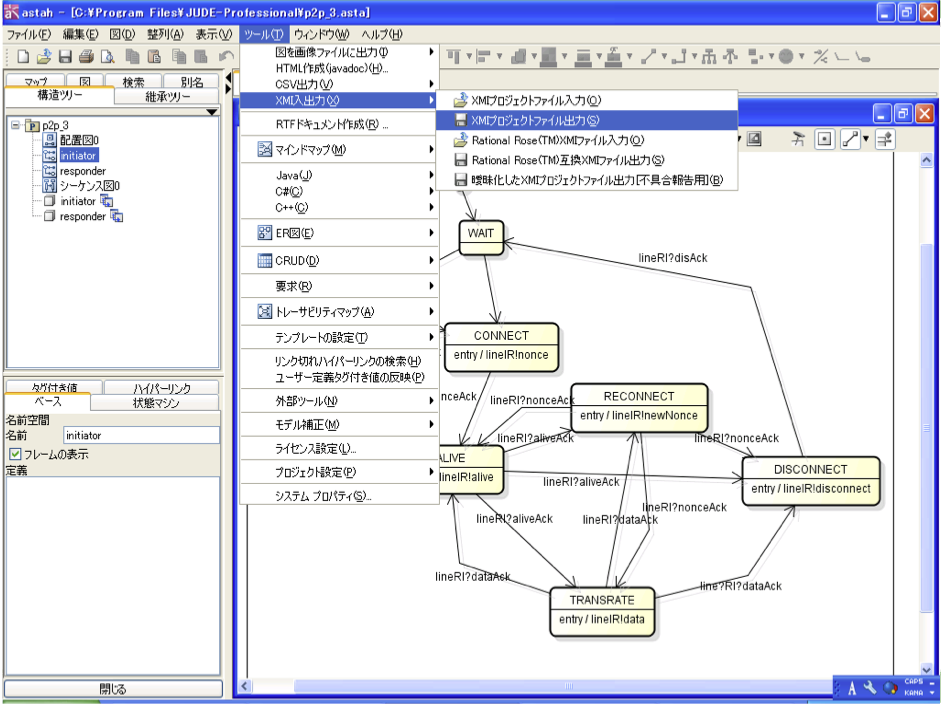
図4.1 UML設計ツール astah* による上位設計の様子と,XMIコードへのエクスポート
SPINは,モデル検査ツールの一種である.SPINの特徴として,分散システムや通信プロトコルなどの,相互通信のシステム検証に使われることが多い.モデル検査の概要とiSPINツールで検査を行っている様子を,図4.2, 4.3 に示す.SPINでモデル検査を実行する際は,専用の仕様記述言語PROMELAを用いてモデルを記述する.PROMELAは,並行して動作するプロセスや,非決定的な振る舞いなどを容易に記述できる特徴を持つ.SPINは,PROMELAで記述されたモデルの表明検査,デッドロック検査等の性質を検証できる.
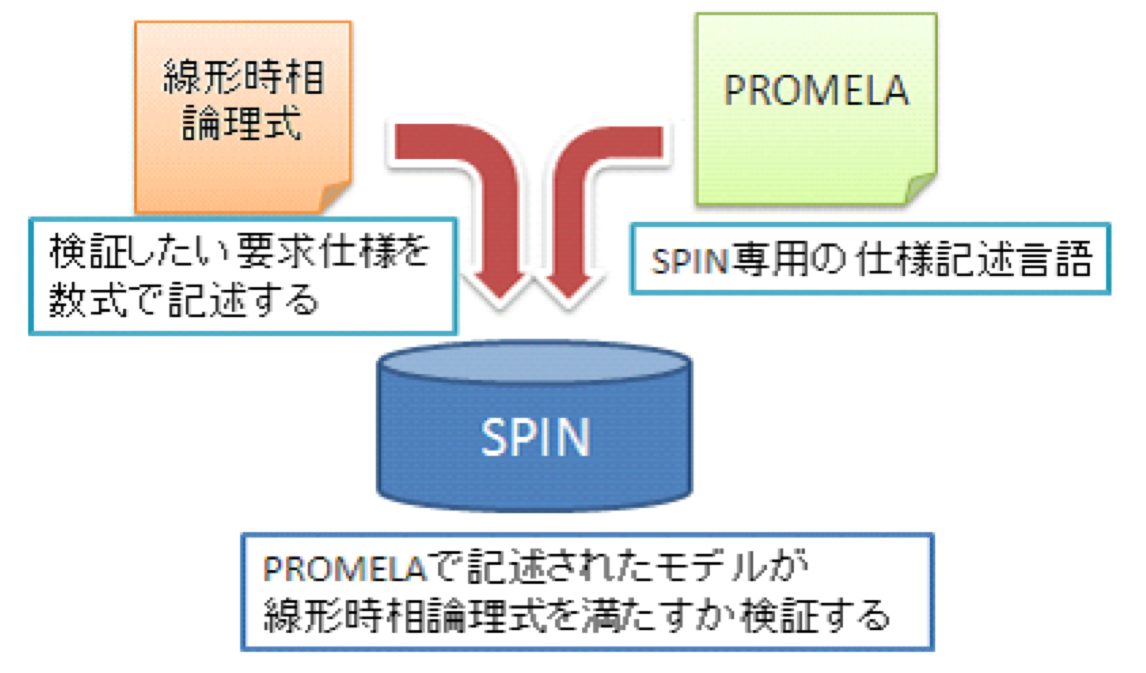
図4.2 PROMELA言語による設計エントリ,ならびに線形時相論理(LTL)式による仕様エントリ
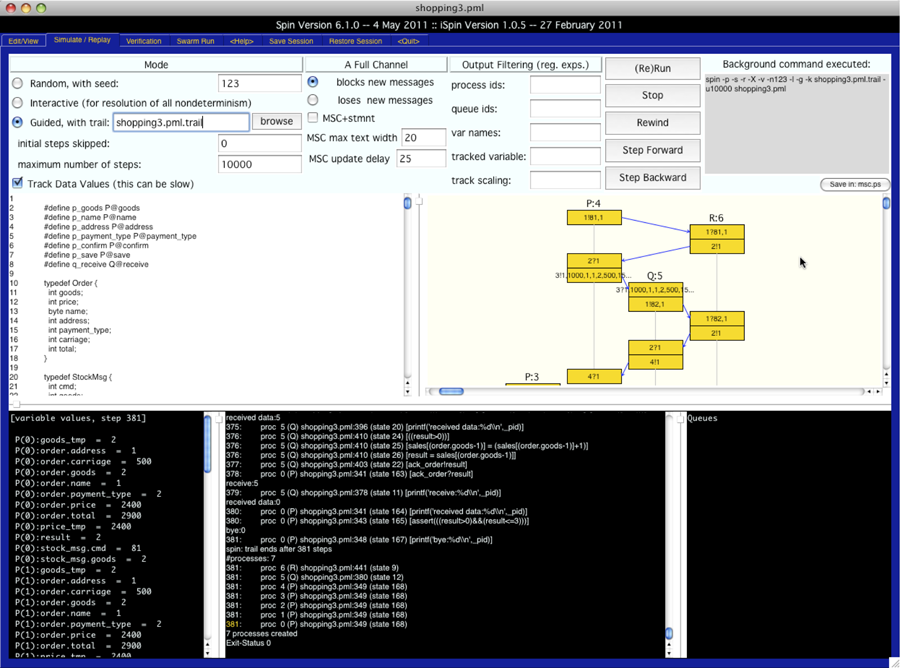
図4.3 SPINモデル検査ツール統合環境 iSPINによる検証とランダムウォーク・シミュレーション実行の様子
時相論理とは,通常の論理式に時間の経過という概念を加えた論理体系である.SPINは,線形時相論理 (LTL) 式 を採用している.LTL式で検査対象論理式を記述することで,SPINは,PROMELAで記述されたモデルが,その論理式を受理するかどうかを自動で検証する.
(2) UML から SPIN 用プロセス定義への自動変換
UMLで記述されたモデルを自動変換することで,上流工程における視覚的了解性を損なうことなく,対象モデルのモデル検査が実行できる.モデルの記述には,UMLのステートマシン図と配置図を用いた.変換器は,Perl言語で実装した.変換の流れは,まず,対象のモデルを,UMLのステートマシン図と配置図で記述する.UML記述ツールは,(株)チェンジビジョン astah* Professional を使用した(図4.1).次に,以下の[A][B]について,各々PROMELA言語コードへ変換・出力する(図4.4の左側のフロー).
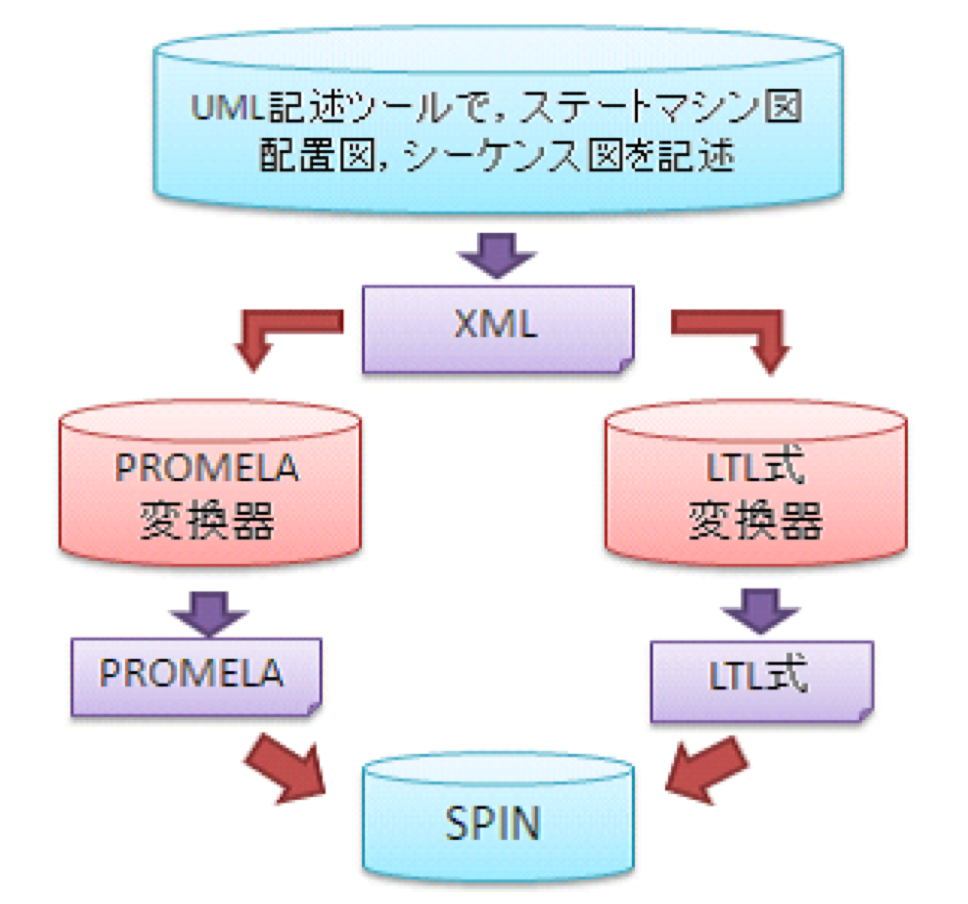
図4.4 UML (配置図・SM図・シーケンス図)から SPIN 用プロセス定義と仕様(PROMELA言語・LTL式)への自動変換の流れ
[A] 状態の定義
ステートマシン図の状態遷移を,PROMELAに変換するため,状態変数を定義する.状態変数には,現在のステートマシン図の状態が格納される.状態遷移時に,状態変数の値も変化する.ステートマシン図では,状態の内部に,新たな状態列が存在するコンポジット状態も記述できる.本研究では,コンポジット状態のPROMELAコードへの変換を検討する.
[B] 通信用チャネルの定義
PROMELAでは,振る舞いをプロセス毎に記述し,プロセス間の通信は,chan型の変数で行われる.自動変換後のプロセスや,通信用チャネルは,UMLの配置図で定義する.通常,配置図は下流工程に用いられる図だが,配置図に用いられるインスタンスやリンク線がPROMELAへの自動変換に適していると判断し,配置図を採用した.配置図のリンク線を,chan型の変数に変換する.
(3) UML から線形時相論理式への自動変換
要求仕様の記述には,変換対象の指定や,インスタンス間の時系列での状態変化が記述できるため,UMLシーケンス図を用いた.シーケンス図で記述された要求仕様から,LTL式への自動変換の流れを図4.4の右側に示す.
[A] シーケンス図の適用範囲
検証したい要求仕様をシーケンス図で記述する.記述された図をLTL式へ自動変換するが,一意に変換するため,シーケンス図で記述する要素を限定する.用いる要素は,ライフライン要素,複合フラグメント要素,メッセージ要素のみとした.
[B] 複合フラグメント
複合フラグメントはモデルの制御構造を表す図法であり,通常は,システム開発の下流工程において用いられる.シーケンス図を,LTL式へ自動変換するためには変換対象となる部位を指定する必要があり,本研究では複合フラグメントを採用し,複合フラグメントのassertフラグメントで囲まれた部位をLTL式への変換対象とする.また,LTL式へ一意に変換するため,変換する要求仕様は,仕様パターンに準拠した.
→もっと詳しく(資料4.1)【PPT】
★キーワード
・形式検証・モデル検査系 SPIN
・UML上位設計
・自動コード生成
・仕様パターン
★このテーマに関する参考資料
[1] The Unified Modeling Language™ - UML
[2] ON-THE-FLY, LTL MODEL CHECKING with SPIN
[3] 宮本, 和崎 : 上流設計からモデル検査プロセスまでの一貫設計検証環境 〜UML 記述から SPIN モデル検査器用プロセス定義及び線形時相論理式への自動変換手法〜 ; 電子情報通信学会 2011年度ソフトウェアインタプライズモデリング研究会ワークショップ, 信学技報(SWIM2011-19), 111(308), 7-12, 2011.
●5. MPI/PCクラスタ・GPGPUによる並列処理
(1) MPI/PCクラスタ
MPI(Message Passing Interface)やOpenMPなどの並列化ライブラリを用いて,プロセッサをネットワークあるいは共有メモリで相互に接続(クラスタ化)し,サイズの大きな計算を均質に並列分散処理させることによって,プロセッサ単独で実行する場合よりも高いコスト/性能比を得るための,種々の並列プログラミングについて研究するものである.ノード構成としては,2次元トーラス,ハイパーキューブなど様々なモデルがある.粗粒度並列計算の用途としては,有限要素解析法の高速並列計算,ファジィ最適制御における決定関数の並列チューニング,遺伝的アルゴリズムの並列化,コンピュータグラフィックスにおける分散フレームバッファを利用した並列レイトレーシングなどの計算,など様々な適用例が存在する.ただし,MPIの場合,メッセージパッシング型であるので,計算性能を出すためには,プログラミングにそれなりの工夫が必要である.OpenMPの場合には,コンパイラが自動並列化を試みる.
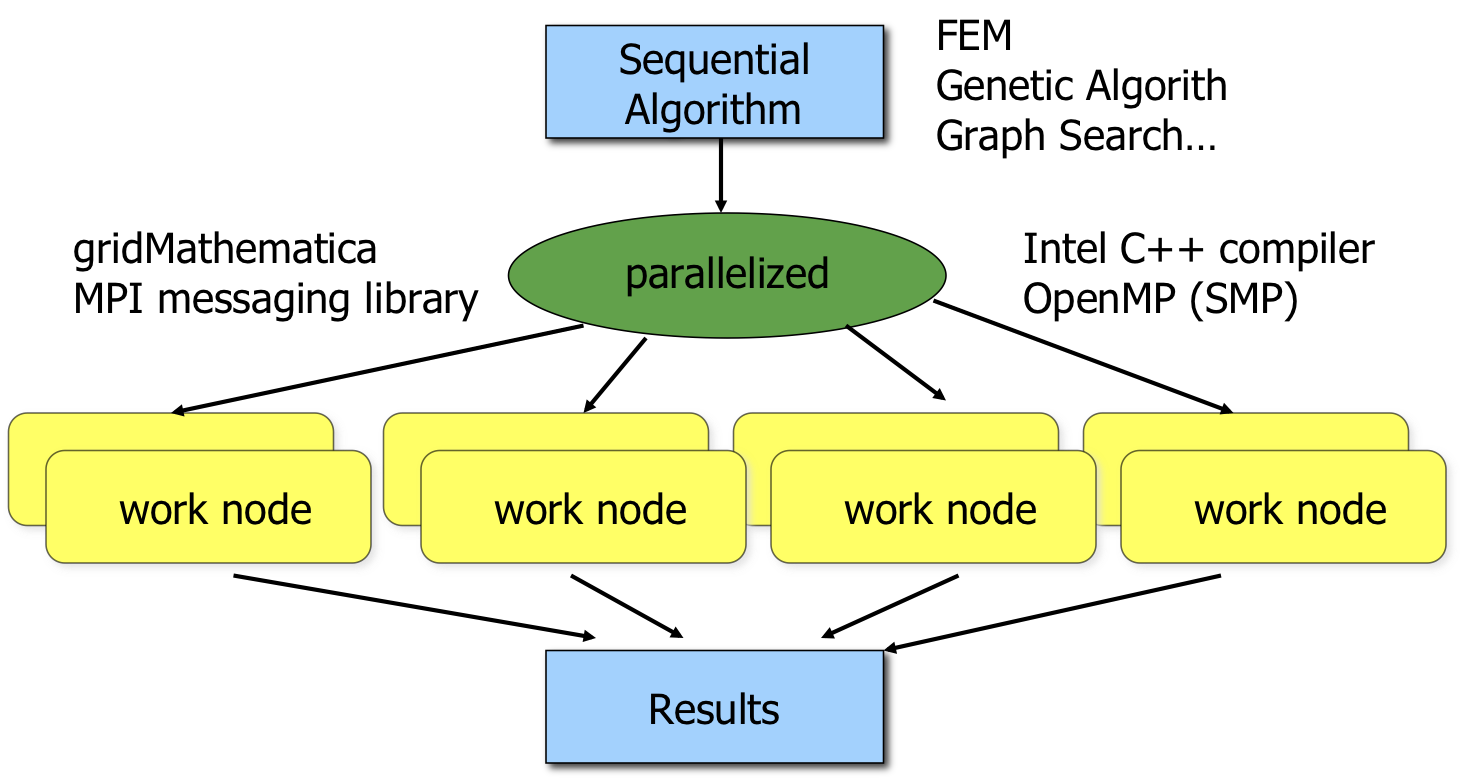
図5.1 逐次アルゴリズムから,手動・自動並列化を経て,クラスタ内の複数ワークノード上で並列計算し,結果をまとめる
MPI/PCクラスタ構成時の,具体的な実験環境は以下の通り(休止中含む).
Linuxシステム:Dual Xeon 3.0GHz×7ノード・Gigabit Ethernet・TurboLinux 10 Server・PVM/MPI並列ライブラリ・intel C++ 自動並列化コンパイラ・gridMathematica
SMPシステム:QuadCore Xeon 2.4GHz x Dual (24GB)・RedHat Enterprise Linux ES5・OpenMP並列ライブラリ・intel C++ 自動並列化コンパイラ
先のテーマで述べた,プロセス代数モデルの,振る舞いトレースグラフLTS生成について,その規模が1台の計算機では大きすぎる場合,MPIクラスタを構成する計算ノードへグラフ生成器を分割実行し,最後にひとつのグラフへまとめる,という工夫がある.ただし,計算ノード数Nに対して性能は線形にしか増加しないので,事前に仕様上ある程度の抽象化を施しておくことが望まれる.
→CADP toolbox LTSグラフ生成器のMPIクラスタ並列化(Distributor)(資料5.1)【PPT】
(2) GPGPUアクセラレータ
GPGPU (General-Purpose computing on Graphics Processing Units) アクセラレータを搭載した並列計算機を使用し,特定の中〜粗粒度並列で効果的な,各種検証アルゴリズムの並列化と高速化に取り組んでいる.
具体的には,ペトリネットモデルの構造解析・動的解析時に,大きなサイズの線形代数演算が必要となっていて,これが検証アルゴリズム上のボトルネックとなっている場合がある.このようなケースでは,線形代数演算が効率的に実行できるよう,事前にある程度のアルゴリズム最適化を施した後,GPGPUを用いた処理に適した並列化ライブラリを用いて,従来の逐次アルゴリズム部分を置き換える,といった改良を行う.

図5.2 HPC用最速パラレルプロセッサ NVIDIA® Tesla™ 20シリーズファミリーGPUイメージ(NVIDIA HPより画像引用)
GPGPUアクセラレータ構成時の,具体的な実験環境は以下の通り(改良中含む).
GPU/HPCシステム:NVIDIA Tesla C2050 (448 Core, 1.03Tflops/peak) + 6Core Core-i7 970 3.2GHz (22GB)・Windows7 Professional 64bit・CUDA並列ライブラリ・CUBLAS並列化線形代数演算ライブラリ
★キーワード
・逐次処理と並列処理の考え方の違い
・並列処理による効率化・問題分割
・ボトルネック,通信オーバーヘッドによる影響
・Flynnの分類
・ネットワークトポロジ
・メモリ共有型 vs 非メモリ共有型
★このテーマに関する参考資料
[1] 参考資料・リンク集:MPI/PCクラスタ並列計算
[2] MPI/PCクラスタを用いた並列有限要素法(メモ)
[3] LAM/MPI : high-quality open-source
implementation of the MPI specification
[4] MPICH
: A Portable Implementation of MPI
[5] GPGPU : HPC用最速パラレルプロセッサ NVIDIA
●指導方針
0.自主的・自律的な学習と行動,提案を期待している.(自己責任 )
1.論理的思考能力の向上に努める.
2.週1回指導教員へ進捗報告と,研究報告会への参加(必ず).
3.講座内外の各種ゼミナールへの参加(適宜).
4.修士課程学生以上については,各種学会研究会・年次大会において発表.
5.博士課程学生以上については,各種国際会議,学術学会誌において発表.
![]()
wasaki _AT_ cs.shinshu-u.ac.jp
Copyright(c) Katsumi Wasaki. All rights reserved.